# EC2
#aws #cloud #compute
The Amazon Elastic Compute Cloud, is an AWS platform for providing cloud-based compute capacity. That means it provides virtual machines in the sky. Where S3 is cloud storage and RDS is cloud relational databases, EC2 gives you a machine where you can run anything you want. Want to run a web server, EC2 can do that. Want to run a database, EC2 can do that.
- AWS Elastic Compute Cloud is a computing web service which provides re-sizeable, secure, and reliable capacity in the cloud
- You have complete control of your EC2 computing resources.
- You can scale rup or scale down the capacity of your EC2 resources as your technical requirements change
- You must pay only for EC2 resources that you use
- You can build and boot new computing instances in only some little minutes
# Instance Types

# Instance Size
# Instance Categories
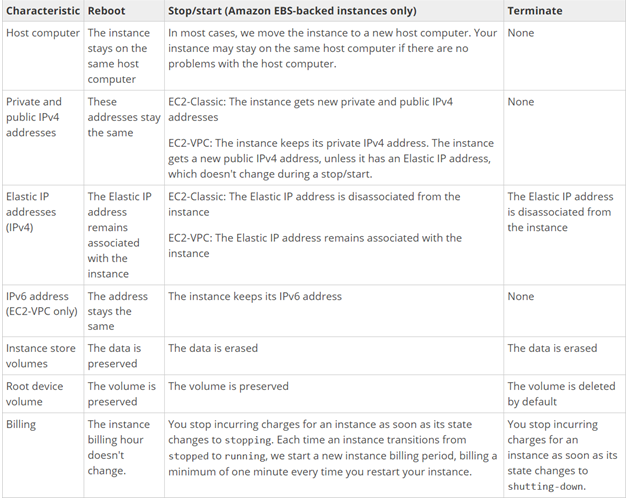
# Instance Pricing
EC2 can be provisioned in various pricing models with their own advantage and disadvantages
The four main types are:
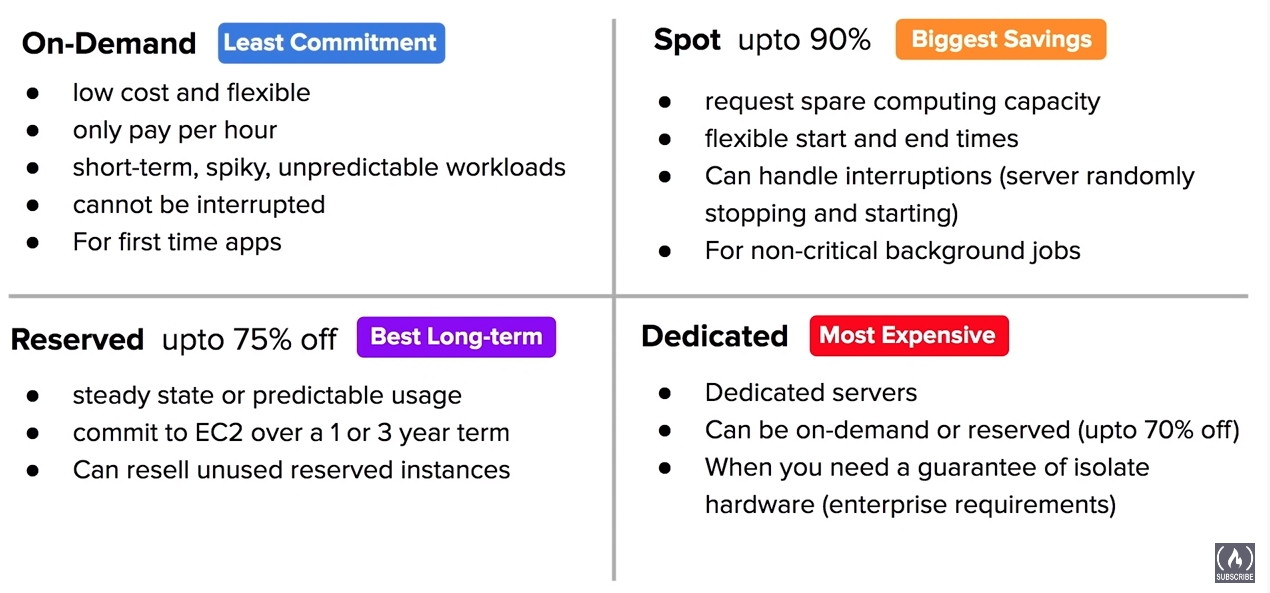
There are also Dedicated Hosts and savings plans.
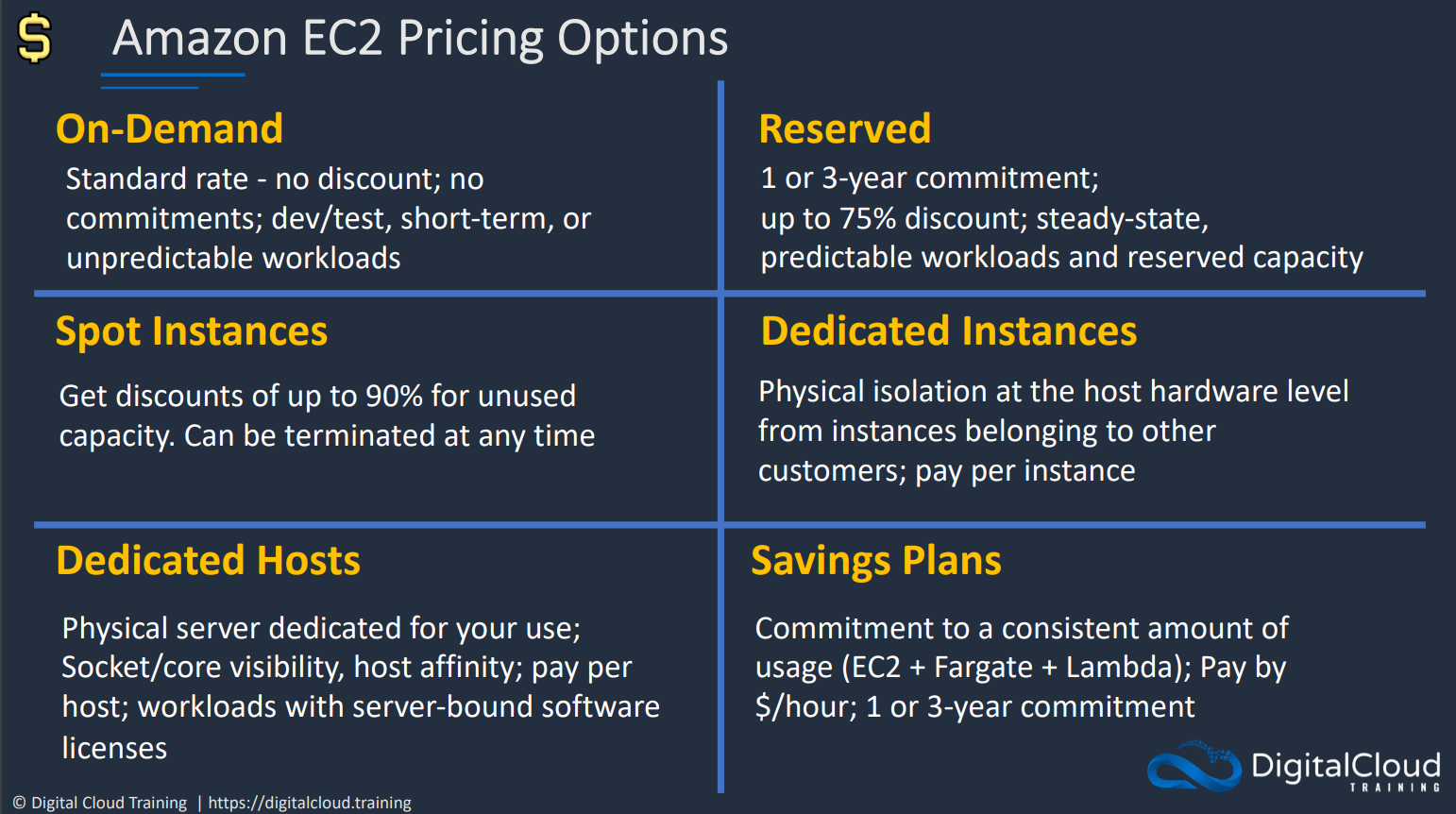
# Reserved Instances
there are two types of reserved instances,

- When the attributes of a used instance match the attributes of an RI the discount is applied.
- the Availability zone and Region should match for the discount to be applied.
- There was a deprecated Scheduled Riserved instance.
# Savings Plans
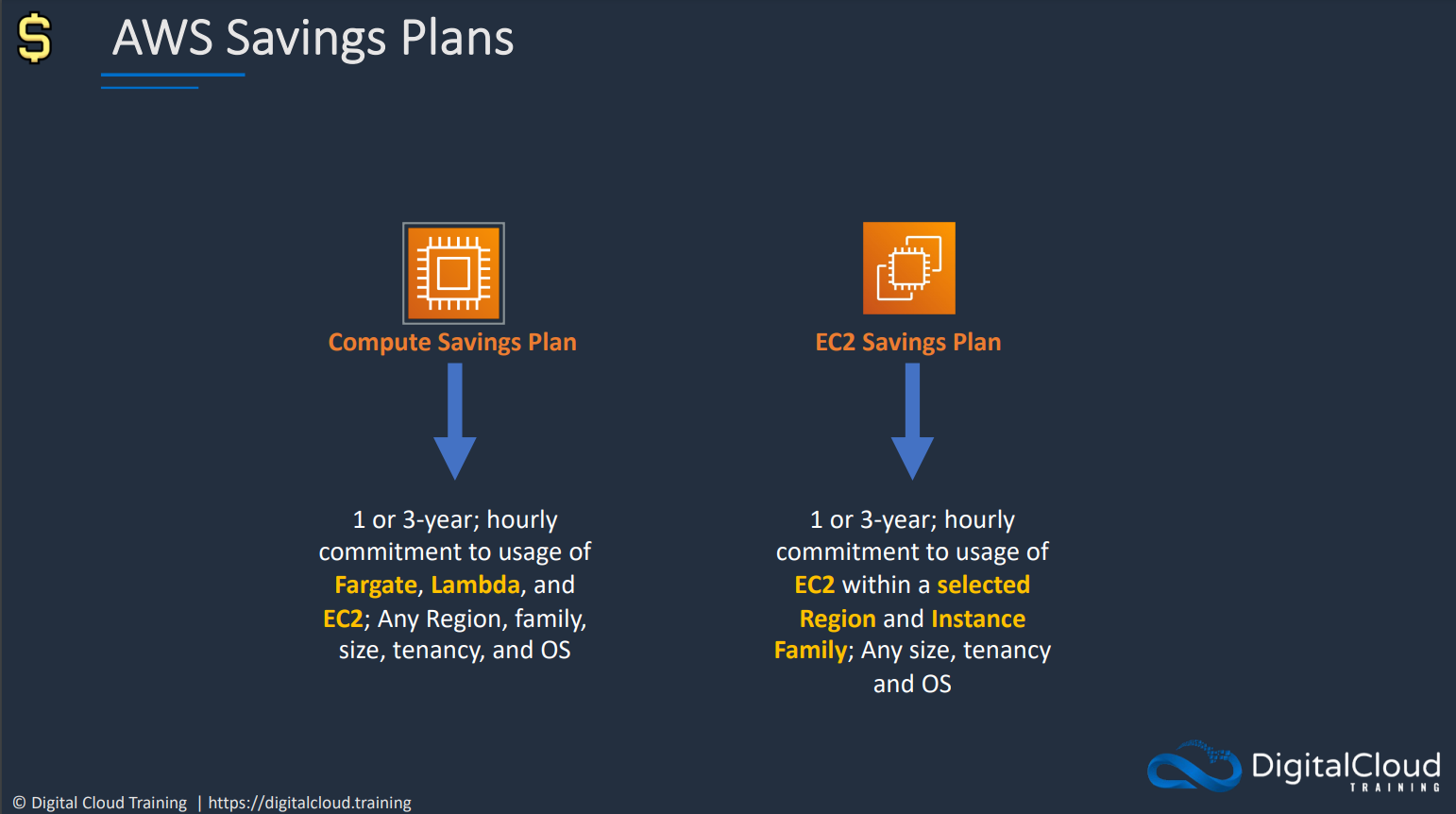
# Spot instances
AWS Provides a cheaper alternative compute solution in EC2 for non important tasks. AWS markets them as “Amazon EC2 Spot instances are spare compute capacity in the AWS cloud available to you at steep discounts compared to On-Demand prices.”
Spot Instances can be utilized as a lone, grouped ot mixed group.

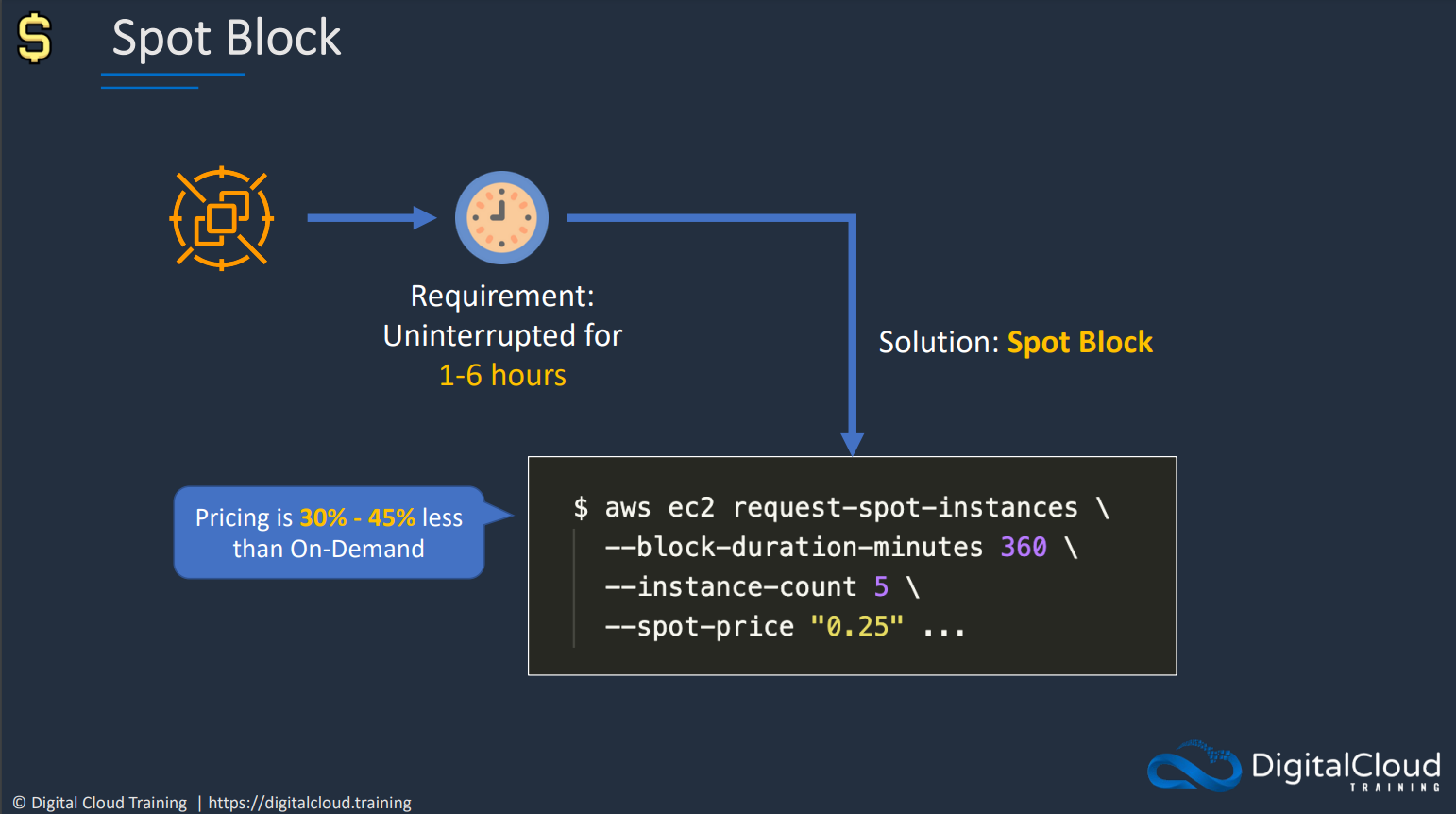
Spot Block can be used to reserved instances for a max of 6 hrs
# Dedicated Instances and Dedicated Hosts
similarly named services for a dedicated instances.

# Use cases:

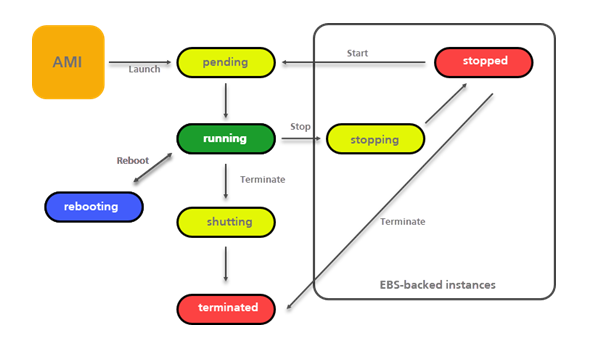
# Instance Status
# Placement Groups
Placement Groups lets you choose the logical placement of your instances to optimize for communication, performance or durability. Placement groups are free


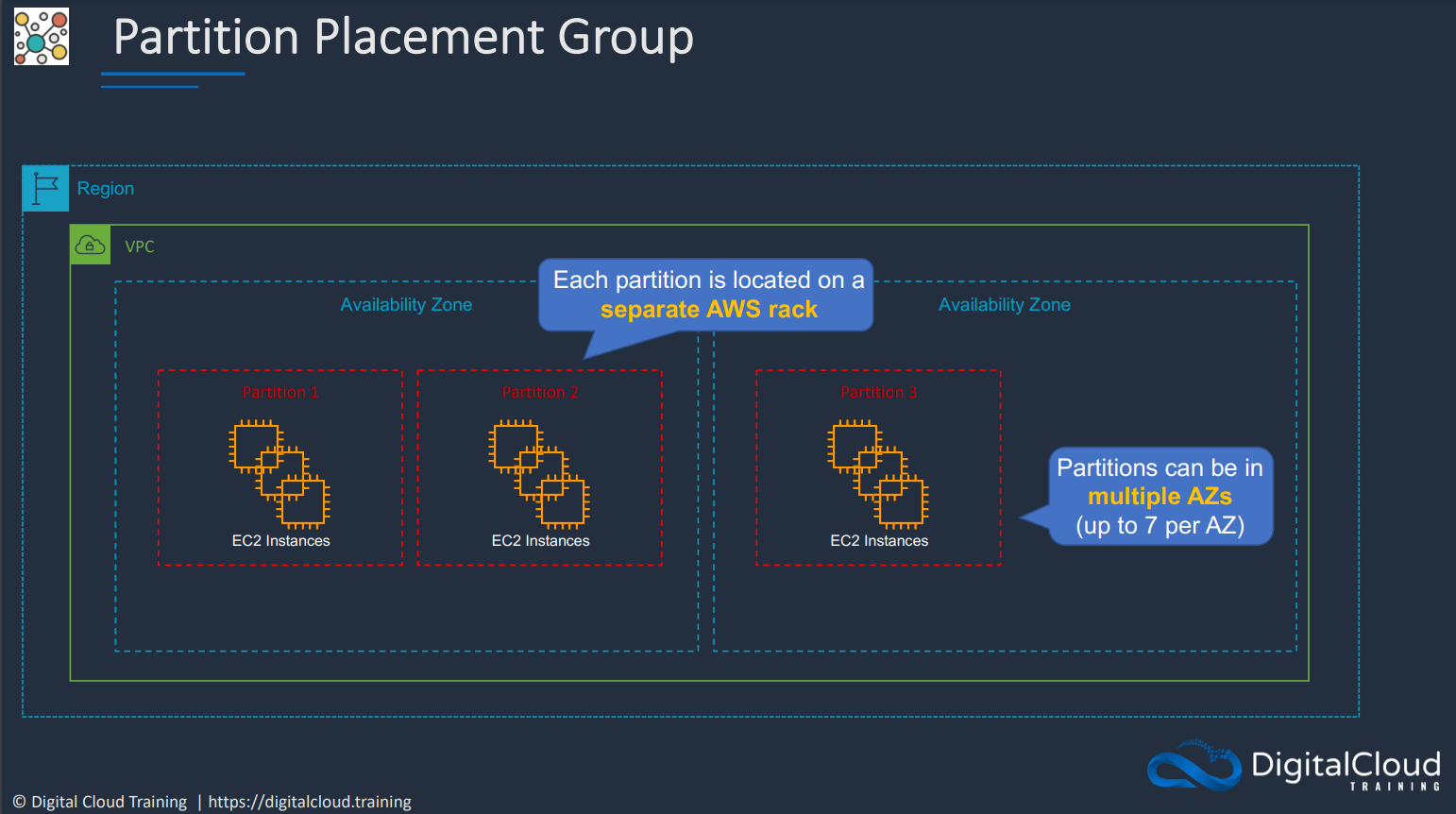

Use cases for placement groups:

# Userdata
A simple bash script that will be run automatically while launching the EC2 instance.
# Metadata
Additional information about the current EC2 instance which you can get from the instance. Can be accessed via http://169.254.169.254/latest/meta-data.
# AMI
Amazon Machine Image (AMI) provides the information required to launch an instance. We can turn EC2 instances into AMIs to make copies of your servers. We can create an ami from an running or stopped ec2 instance. While launching a new instance we will need to pick an AMI with the operating systems and configurations of our choice. AMIs have different IDs on different regions. We can make copies of our AMIs which will let you transport AMIs to other regions or even accounts using copy ami command.
Use cases:
- Help you keep incremental changes to your OS, application code and system packages.
- Can be configured with Systems Manager Automation to routinely patch your AMIs with security updates
- Is required to launch new instances in the autoscaling groups as it is required to create a launch configuration/launch template.
# Storage Options
# Network Options
# Security Options
# Instance Profile
Instead of embedding your AWS access key, you can attach a role to an instance via an Instance Profile. It holds a reference to a role. The EC2 instance is associated with the Instance Profile. Basically a container for an IAM role that you can use to pass role information to an EC2 instance when the instance starts.
# Auto Scaling Groups
Set scaling rules which will add or reduce ec2 instance in an group to meet the demand of the traffic.
# ASG-Capacity Settings
The size of tan ASG is based on Min, Max and Desired Capacity.
ASG will always launch instances to meet minimum capacity.
# Health Check Replacements
# 1. EC2 Health Check
EC2 health check watches for instance availability from hypervisor and networking point of view. For example, in case of a hardware problem, the check will fail. Also, if an instance was misconfigured and doesn’t respond to network requests, it will be marked as faulty.
# 2. ELB Health Check
ELB health check verifies that a specified TCP port on an instance is accepting connections OR a specified web page returns 2xx code. Thus ELB health checks are a little bit smarter and verify that actual app works instead of verifying that just an instance works.
# 3. Custom Health Check
If your application can’t be checked by simple HTTP request and requires advanced test logic, you can implement a custom check in your code and set instance health though API: Health Checks for Auto Scaling Instances
# Scaling Polices
Scale out or in to add or remove instances in an ASG. Amazon’s EC2 Auto Scaling provides an effective way to ensure that your infrastructure is able to dynamically respond to changing user demands. For example, to accommodate a sudden traffic increase on your web application, you can set your Auto Scaling group to automatically add more instances. And when traffic is low, have it automatically reduce the number of instances. This is a cost-effective solution since it only provisions EC2 instances when you need them. EC2 Auto Scaling provides you with several dynamic scaling policies to control the scale-in and scale-out events.
# 1. Simple Scaling
Simple scaling relies on a metric as a basis for scaling. For example, you can set a CloudWatch alarm to have a CPU Utilization threshold of 80%, and then set the scaling policy to add 20% more capacity to your Auto Scaling group by launching new instances. Accordingly, you can also set a CloudWatch alarm to have a CPU utilization threshold of 30%. When the threshold is met, the Auto Scaling group will remove 20% of its capacity by terminating EC2 instances.
When EC2 Auto Scaling was first introduced, this was the only scaling policy supported. It does not provide any fine-grained control to scaling in and scaling out.
# 2. Target Tracking
Target tracking policy lets you specify a scaling metric and metric value that your auto scaling group should maintain at all times. Let’s say for example your scaling metric is the average CPU utilization of your EC2 auto scaling instances, and that their average should always be 80%. When CloudWatch detects that the average CPU utilization is beyond 80%, it will trigger your target tracking policy to scale out the auto scaling group to meet this target utilization. Once everything is settled and the average CPU utilization has gone below 80%, another scale in action will kick in and reduce the number of auto scaling instances in your auto scaling group. With target tracking policies, your auto scaling group will always be running in a capacity that is defined by your scaling metric and metric value.
# 3. Step Scaling
Step Scaling further improves the features of simple scaling. Step scaling applies “step adjustments” which means you can set multiple actions to vary the scaling depending on the size of the alarm breach.
When a scaling event happens on simple scaling, the policy must wait for the health checks to complete and the cooldown to expire before responding to an additional alarm. This causes a delay in increasing capacity especially when there is a sudden surge of traffic on your application. With step scaling, the policy can continue to respond to additional alarms even in the middle of the scaling event.
Here is an example that shows how step scaling works:
