# Amazon Athena
#cloud #aws #data-analytics
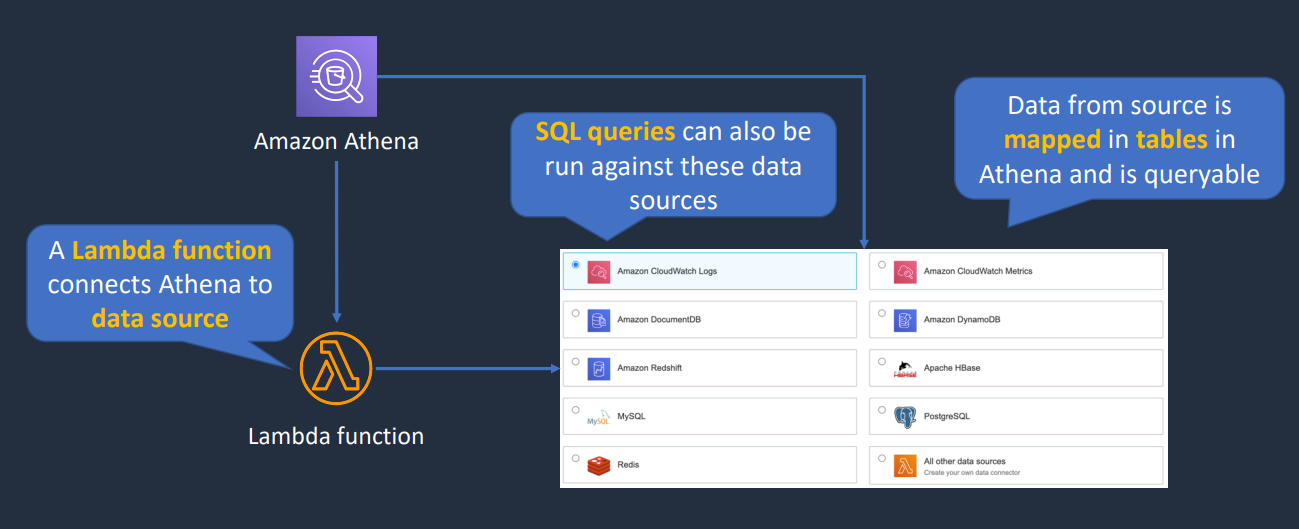
A serverless service from AWS to run SQL queries against data stored in S3 like CSV, TSV, JSON, PARQUET, and ORC formats. You can also use AWS Glue as a data catalog which stores the metadata information and schema about the databases and tables. • Can be connected to other data sources with Lambda to query the data sources from places like CloudWatch Logs, Redshift, etc.
# Optimizing for Performance
• Partition your data • Bucket your data – bucket the data within a single partition • Use Compression – AWS recommend using either Apache Parquet or Apache ORC • Optimize file sizes • Optimize columnar data store generation – Apache Parquet and Apache ORC are popular columnar data stores • Optimize ORDER BY and Optimize GROUP BY • Use approximate functions • Only include the columns that you need
https://aws.amazon.com/blogs/big-data/top-10-performance-tuning-tips-for-amazon-athena/