# DP-900
#Azure #cloud #dataanalytics #datawarehousing
Azure exam prep
# Core Data related Azure Services
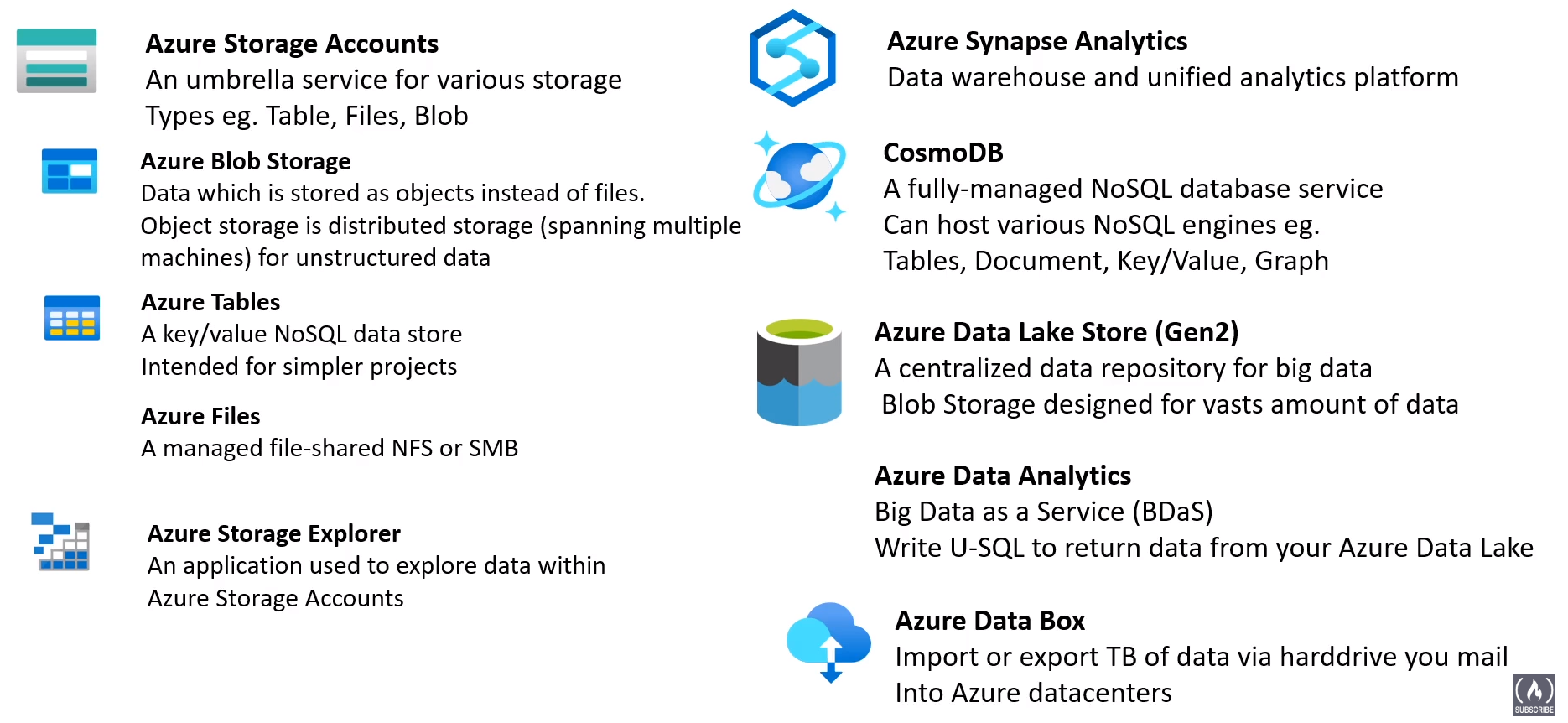
Azure Storage Explorer (To explore Azure Storage accounts)
Azure Synapse Analytics
Azure Data Lake Storage
Azure Data Analytics
Azure Data Box
Azure Databricks (Apache spark 3rd party)
Microsoft Power BI (Dashboards)
HDInsight (fully managed Hadoop)
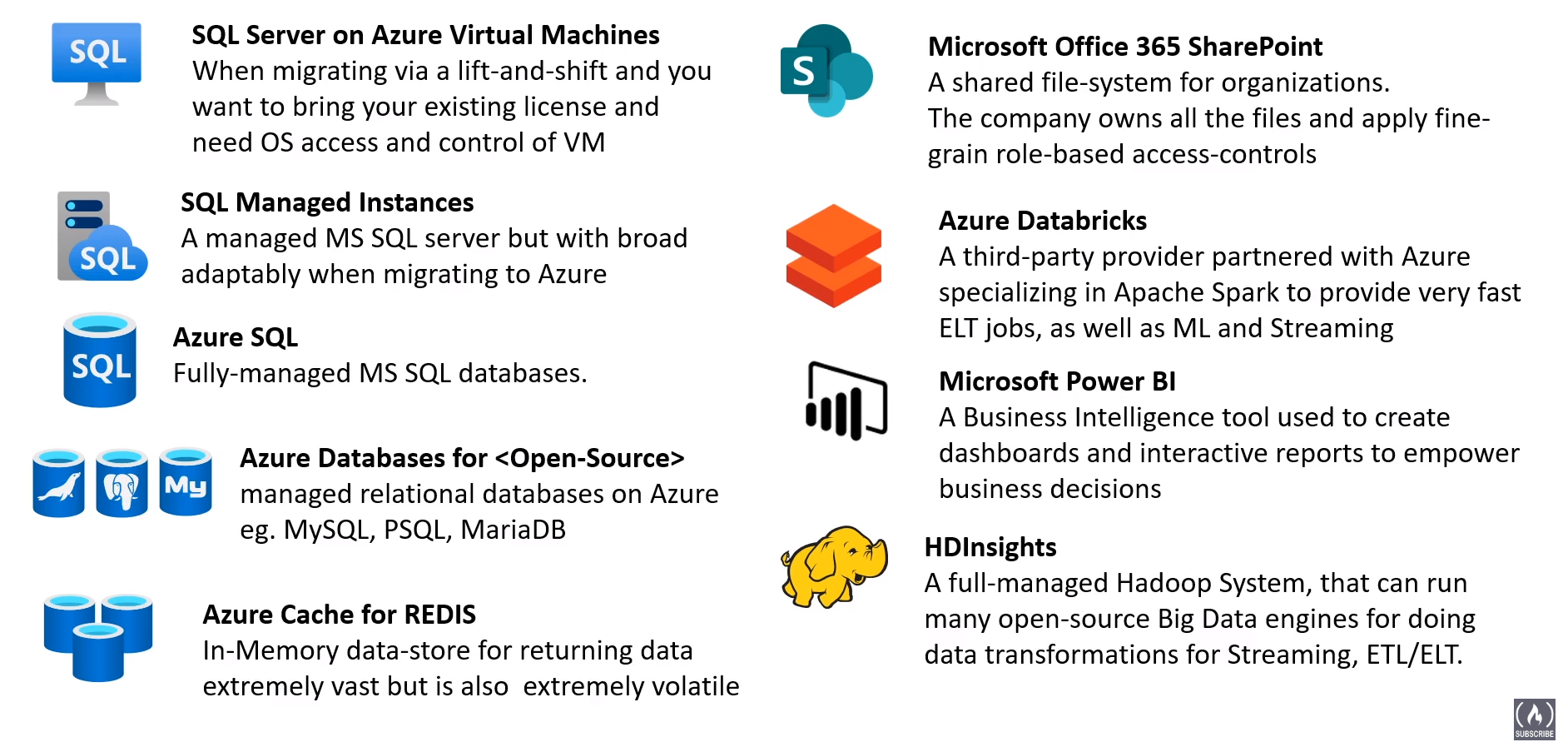
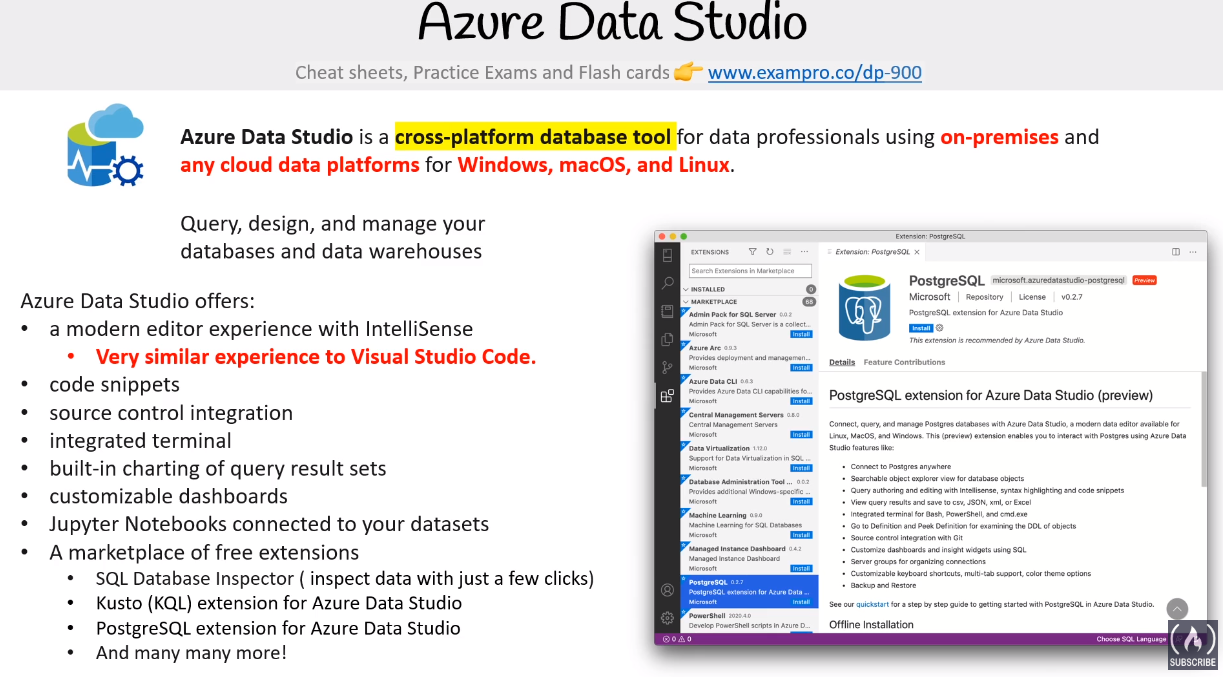
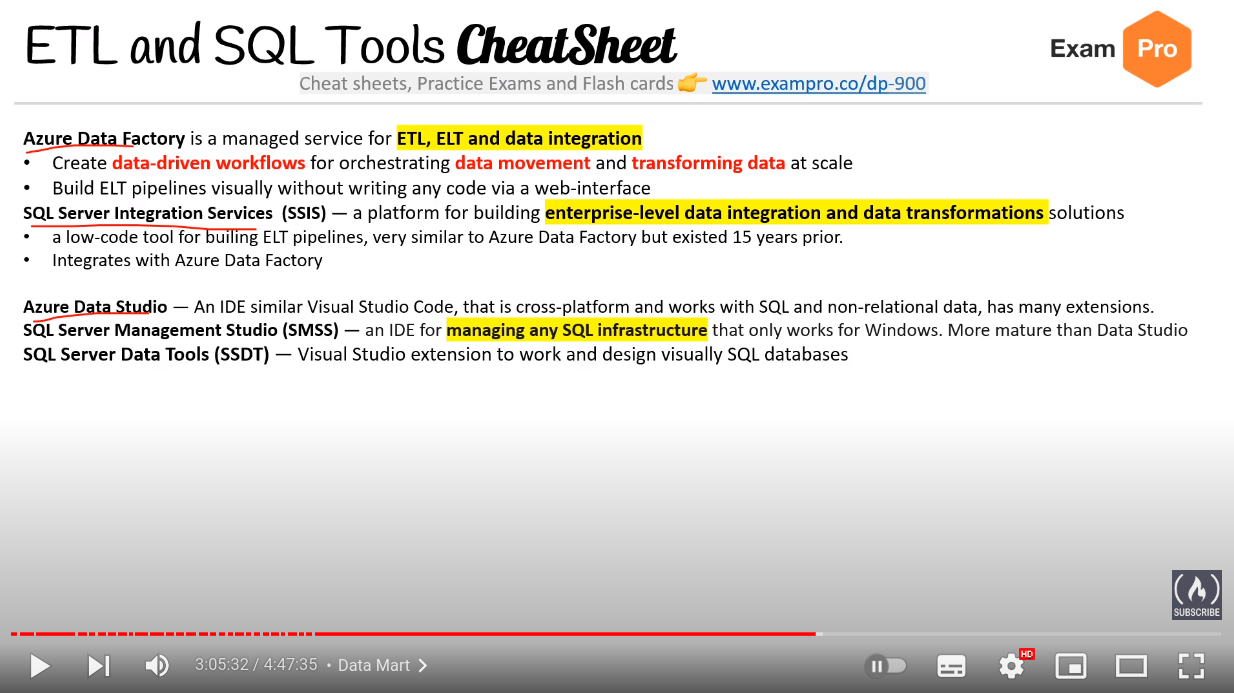
Azure Data Studio (IDE like VSCode for data related tasks similar to SSIS)
Azure Data Factory (ETL/ELT pipeline builder)
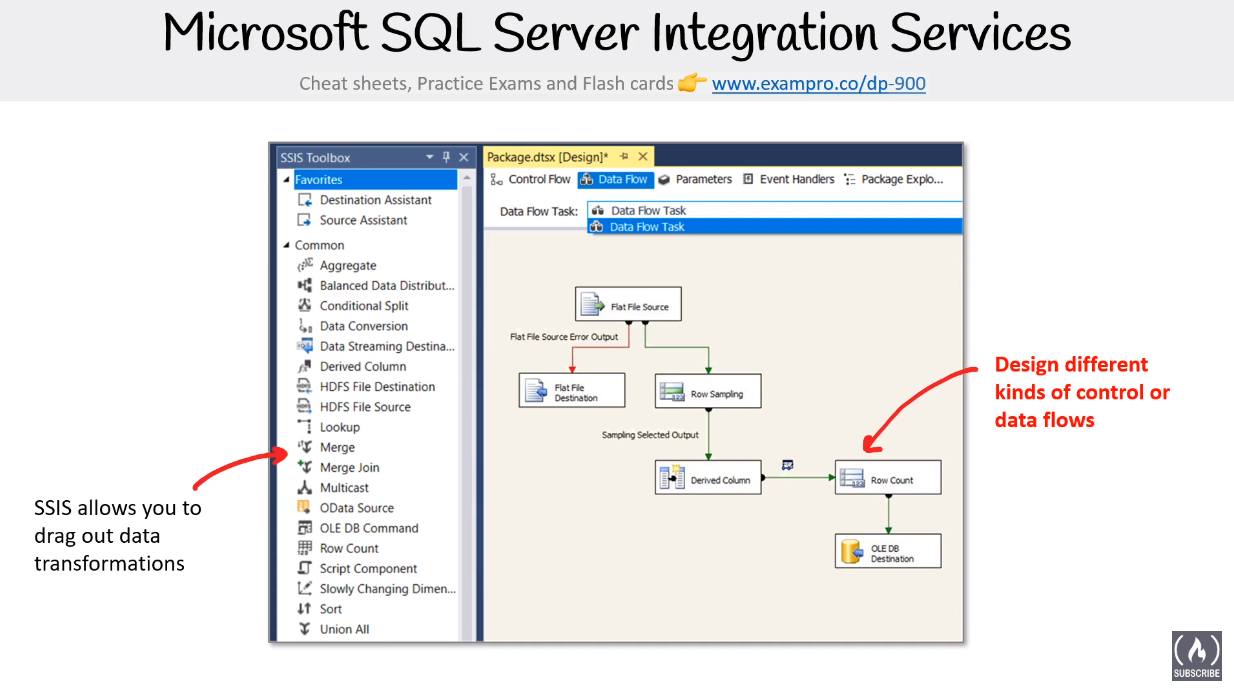
SQL Server Integration Services (SSIS)

# Azure Data Roles

# Data Engineer Tools

# Data Overview
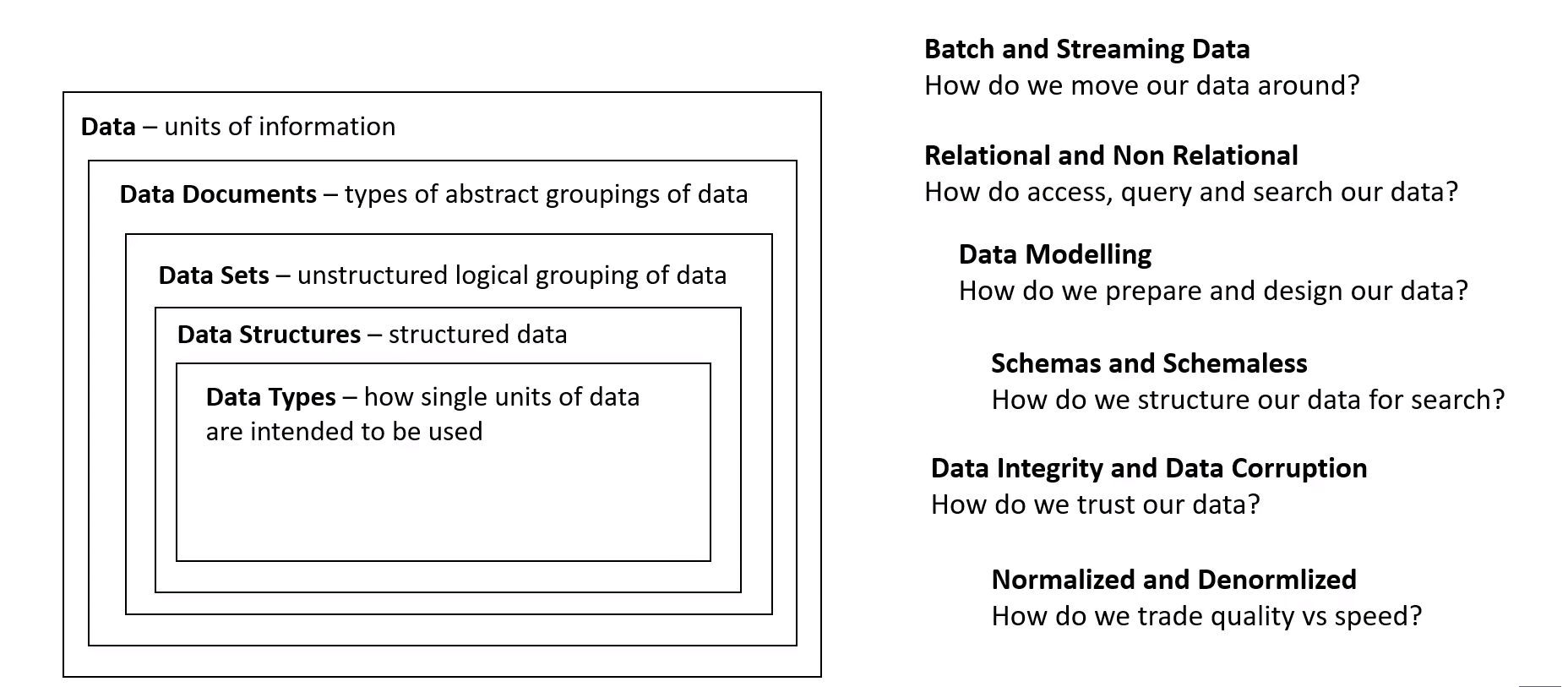
# Data
Basically Information
# Data Documents
Collective Data (Datasets, Databases, Datastores, Data warehouses, notebooks)
# Datasets
Logical Grouping of units of data (mnist, Stackoverflow developer dataset, etc)

# Data Structure
a specific storage format.
- unstructured (Sharepoint, blob, azure files, Azure Data Lakes)
- semi-structured (slight relations XML, JSON, AVRO, PARQUET) (Azure Tables, Cosmos DB, Mongo, Cassandra)
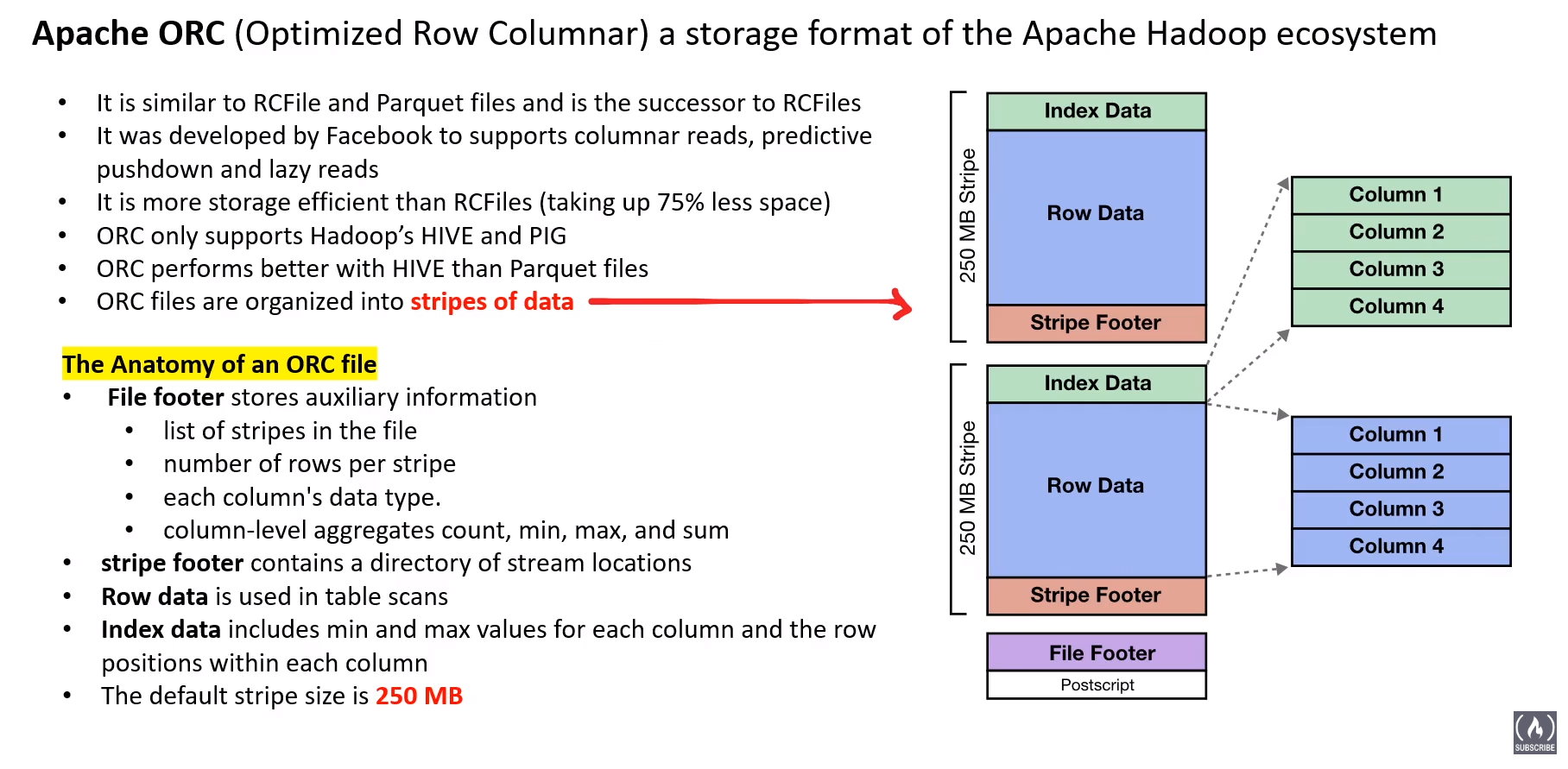
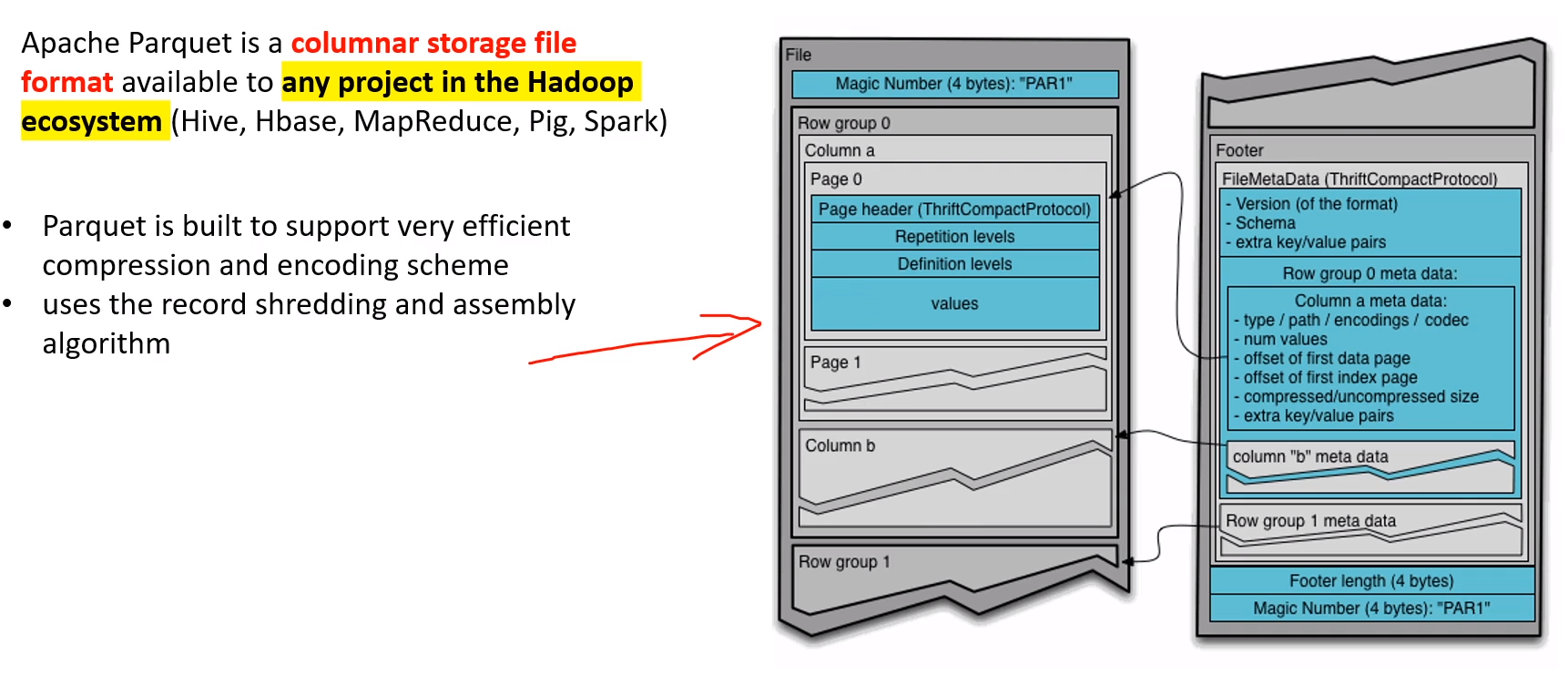
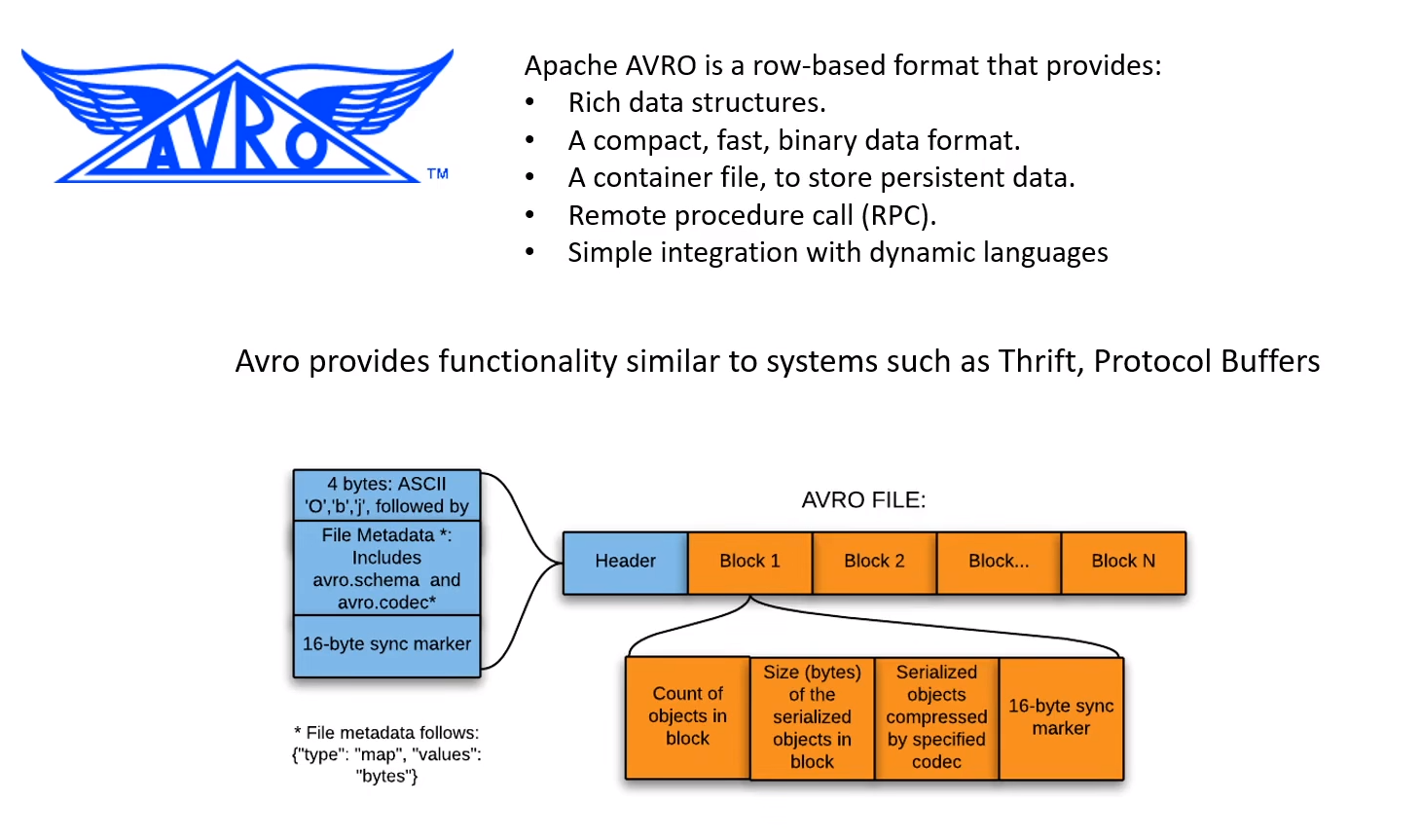
- structured usually just tables
# Data Type
Single unit of data to tell a computer how a data is intended to be used (Int, Float, Characters, String, Array, Hash, Binary, bool, enums etc) some of these overlap with data structures
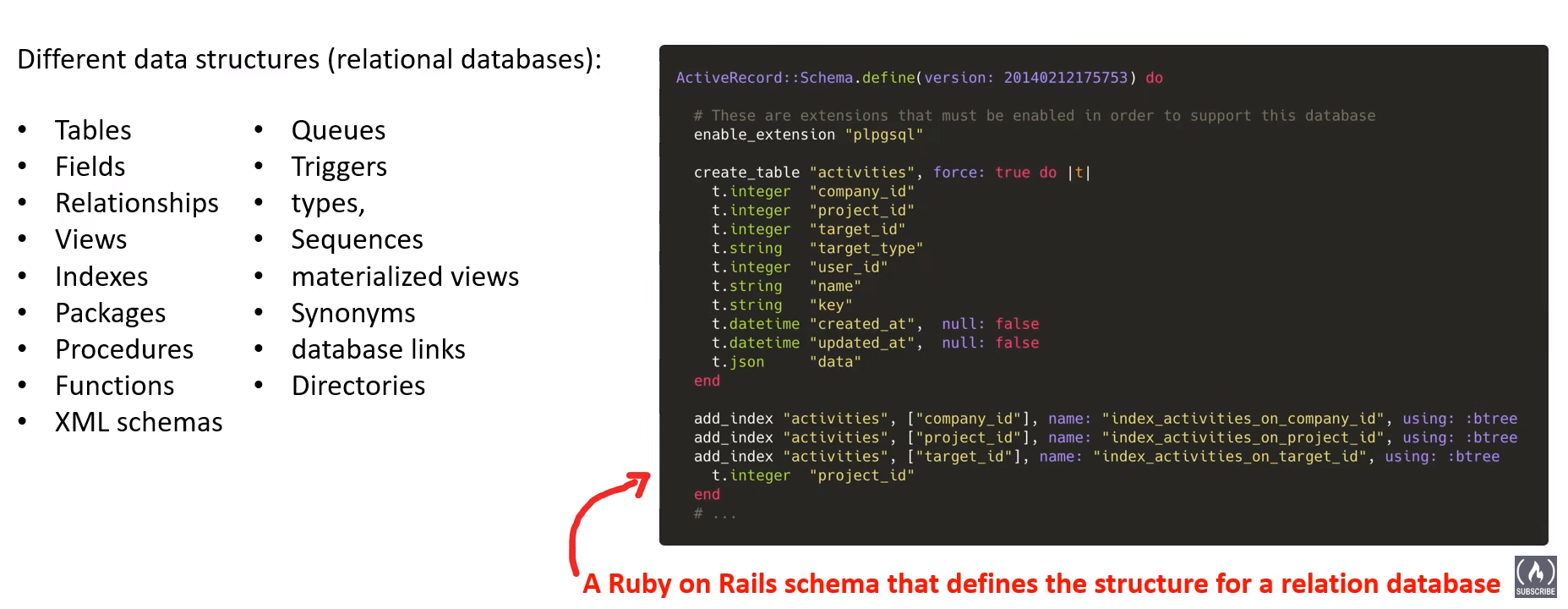
# Schema
Blueprint of database
# Schemaless
A cell can accept many types related to Nosql Databases
# Batch Processing
Usually a scheduled action to process a collection of data, are cost effective and is not real-time (ie, analysing daily logs)
# Stream Processing
For realtime data processing Producers send to stream and Consumer pull from stream
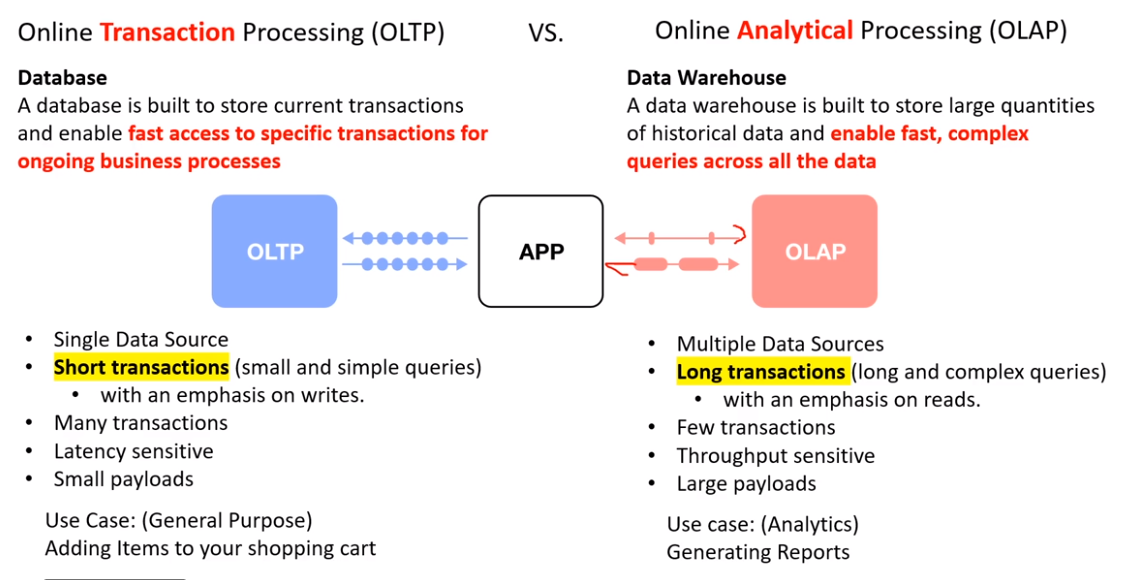
# Relational Data
Tables: Logical grouping of rows and columns Views: Result of query which is stored in memory (Temp table) Materialized View: similar to Views but stored on disk Indexes: copy of a column to accelerate stuff (By storing partial redundant data) Constraints: Rules for writes Triggers: A function triggered on a certain database event PK/FK: A data to create relationship between tables
Row Store: generally used in relational database Column Store: NoSQL Faster for analytics, good for large amounts of data (OLTP), for limited columns use
Pivot Tables: A table of statistics easy to create in Excel to draw attention to useful information and finding figures and facts quickly.
Data Consistency: when data is kept in many places and weather they match or not. (Strongly consistent vs Eventually Consistent). Syncronous data transmissions are used in Strongly consistent data.
# Non Relational Data
- Key/Value
- Document
- Columnar
- Graph
# Data Sources
Where Data originates from, can be: Data lake Data warehouse Datastore Database Data requested from API Flat Files (spreadsheet)
# Data Store
A repo for storing data, Database is a subset of data store
# Database
Stores semi-structured or structured data A more complex data store with a formal design
# Data Warehouse
A relational data store for analytic workloads, utilizing usually column-oriented data-store to aggrigate huge amounts of data. they are desined to be HOT (fast). They are run in a schedule. It needs to consume data from a relational database.
# Data Mart
Subset of Datawarehouse which stores a smaller sets of data and are designed to be read only.
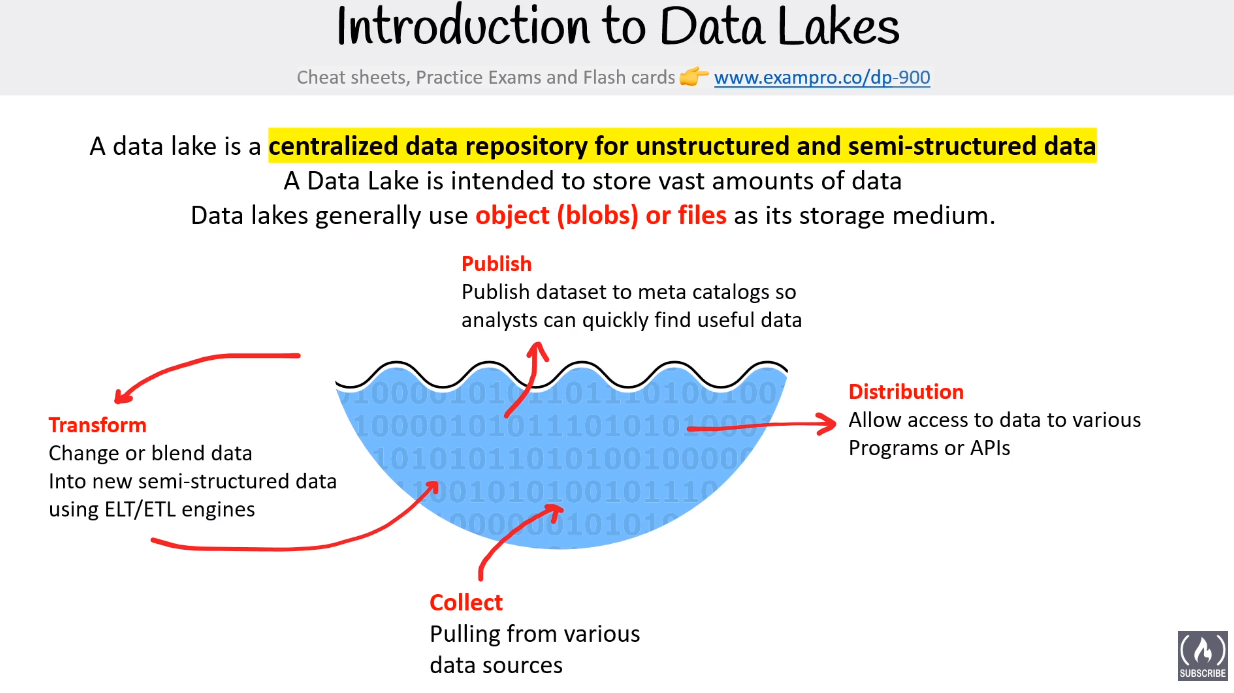
# Data Lake
A centralized place to store vast amount of raw data. Used for:
Visualization
Real-time analytics
Machine Learning
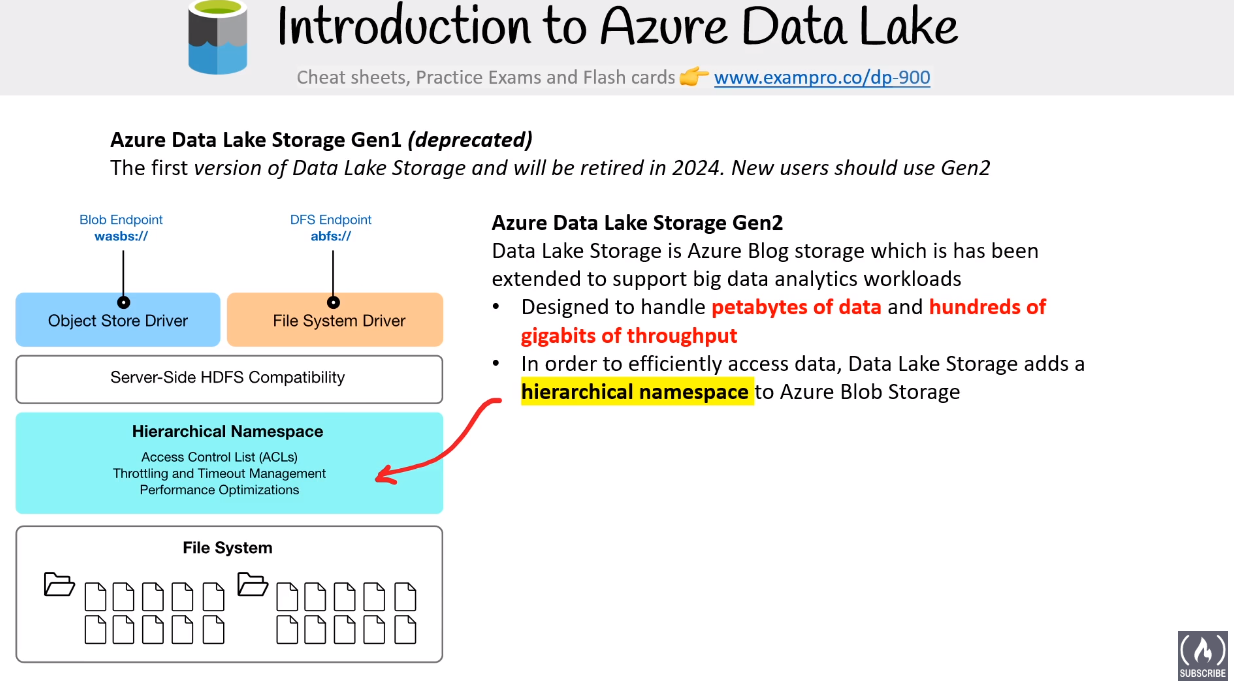
# Data Lakehouse
Combines the best elements of Data Lakes and Data warehouse. Supports video, audio and text files, used for data science and ML. support for both streaming and ELT
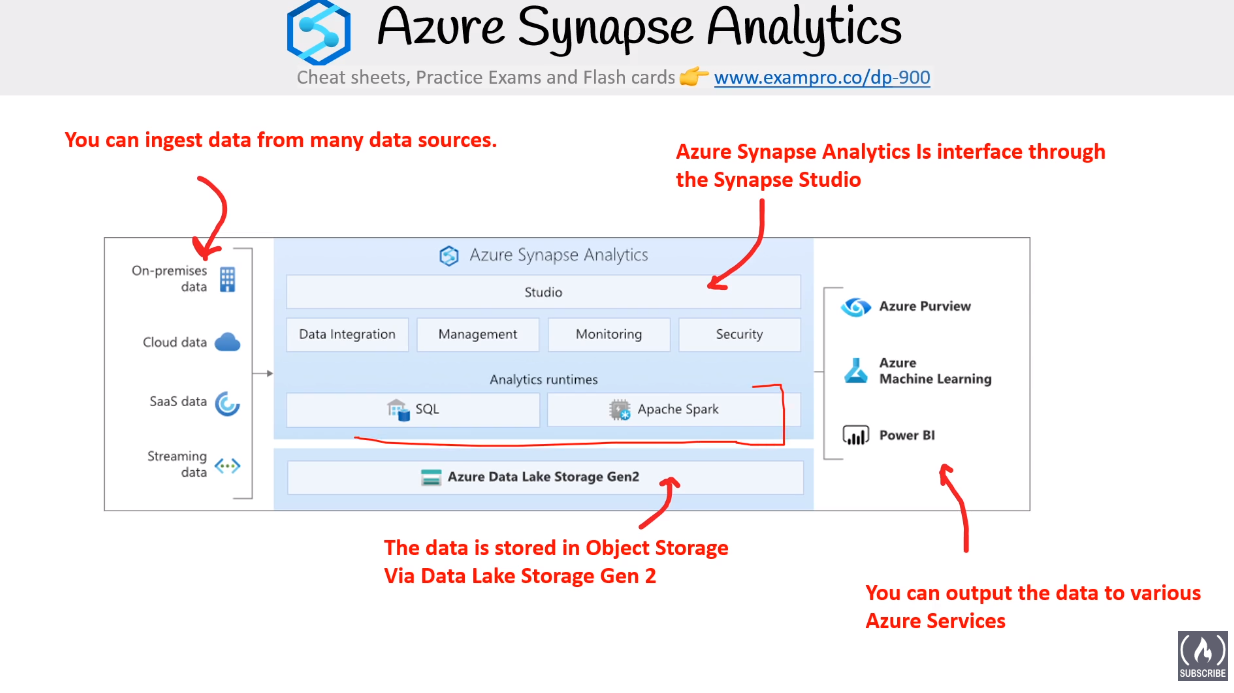
# Azure Synapse
Basically Data Lake or LakeHouse service by Azure
 Synapse SQL
Synapse SQL
- Extends TSQL for ML
- streaming capabilities to load data
- Integrate AI with SQL
- Offers both serverless and dedicated resource models
Features:
- Integrate with Apache Spark (SparkML, )
- Simplified resource model
- Fast spark load
- Built in support for dotnet
- makes it easy to use SQL and spark
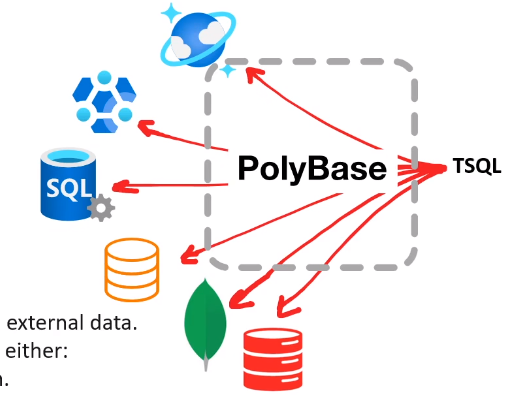
# PolyBase
Data virtualization feature for Sql Server Query directly TSQL from
- SQL server
- Oracle
- Teradata
- MongoDB
- Hadoop clusters
- Cosmos DB
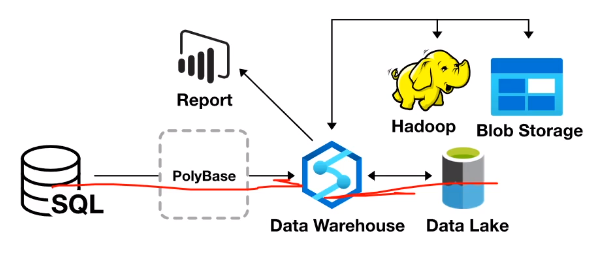
 can bu used to perform ETL transformation
can bu used to perform ETL transformation
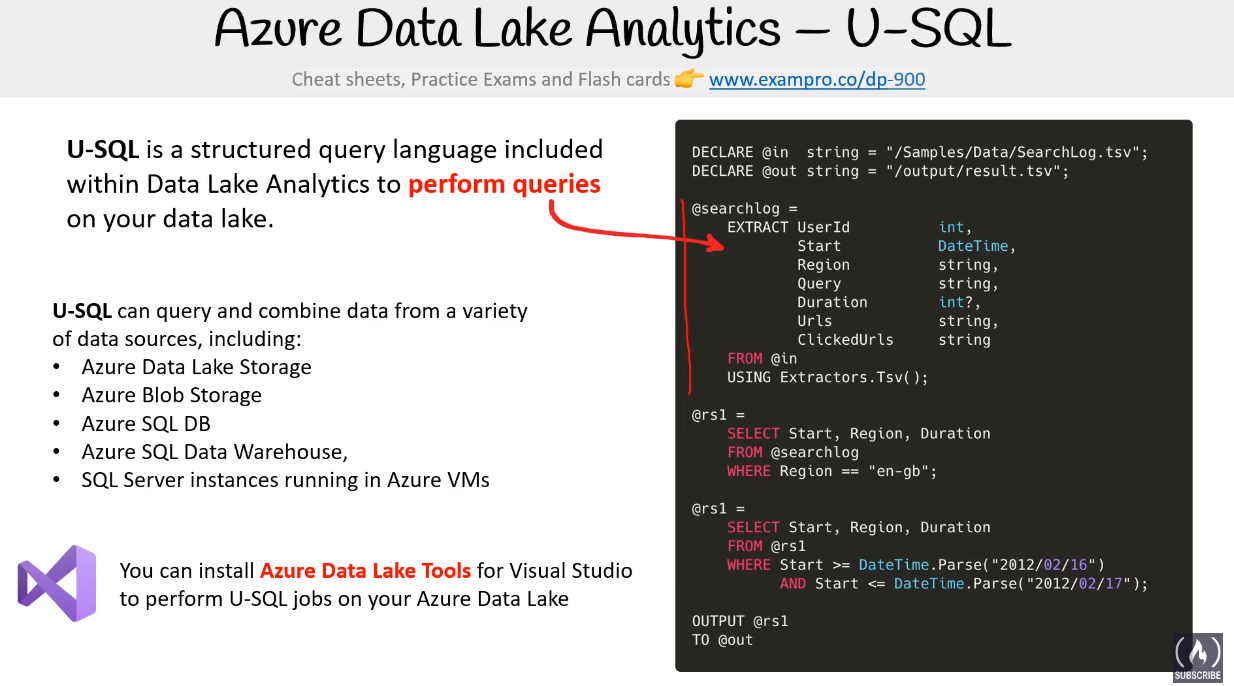
# Azure Data Lake Analytics
On demand analytics job service
# Data Mining
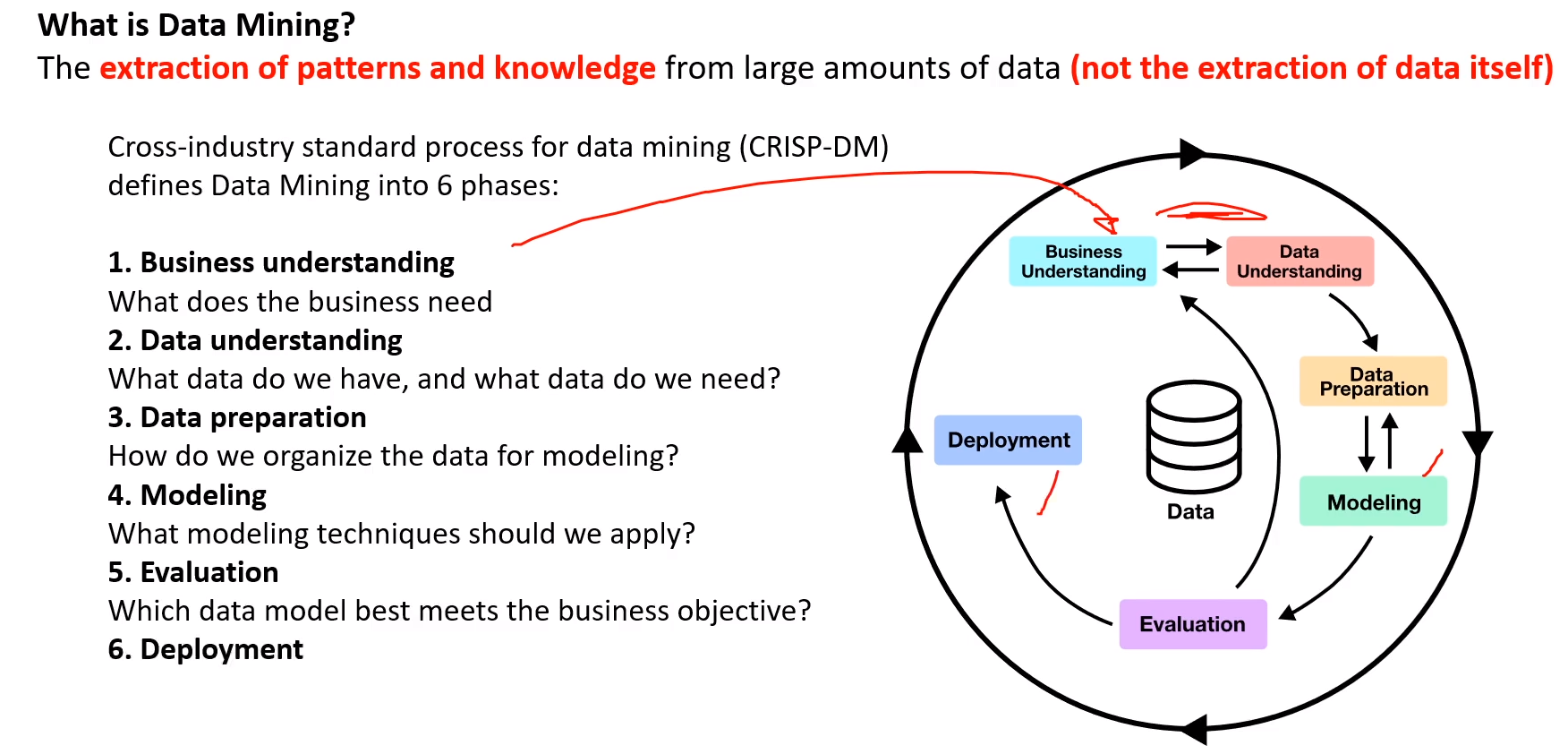 find valid patterns and relationships (classification, clustering, regression, sequential, association rules, Outer Detection, Prediction).
find valid patterns and relationships (classification, clustering, regression, sequential, association rules, Outer Detection, Prediction).
# Data Wrangling
Matching data from raw to other format.
# Data Modelling
Organizing elements of data and standardises how they relate to one another. could be conceptial, logical or physical. example a ER diagram.
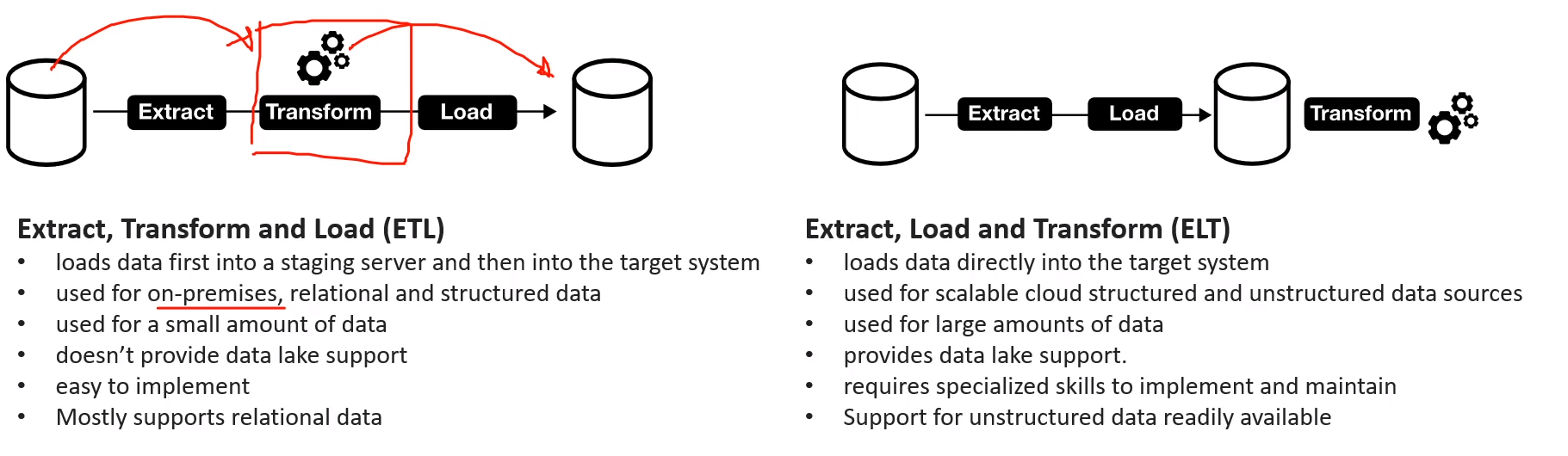
# ETL vs ELT
used when you want to move data from one location to another. Ie moving data from relational to non relational database
# Data Analytics
Examining, transforming and arranging data to view useful information.
Techniques Descriptive Diagnostic Predictive Prescriptive Cognitive
# Azure HDInsights
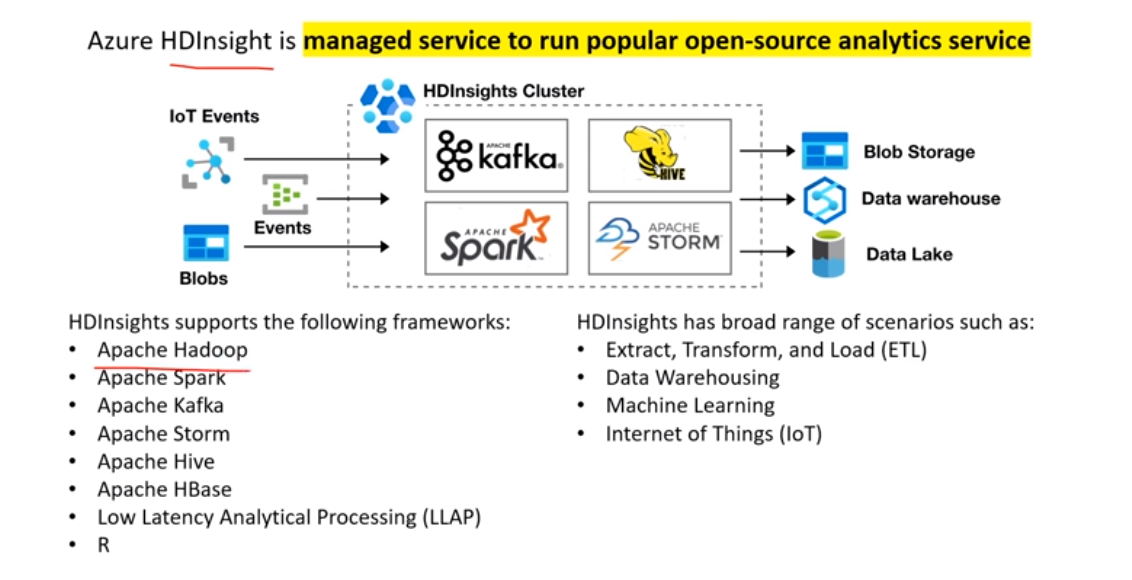 Can use Apache Ambari an opensource Hadoop implementation
Can use Apache Ambari an opensource Hadoop implementation
Apache spark is a unified analytics engine for BD and ML.
- Super fast
DataBricks Fully managed Spark Clusters. Available on all major cloud platform. Azure Data Bricks is a partnership with Databricks to offer the services within Azure.
- Azure Data-bricks Workspace (for data pipelines: Batching, Streaming, Storage)
- Azure Database SQL Analytics (run SQL on Data Lakes, visualizations, dashboards)
Azure certification for data foundations DP-900 done after
DP 900
Power BI
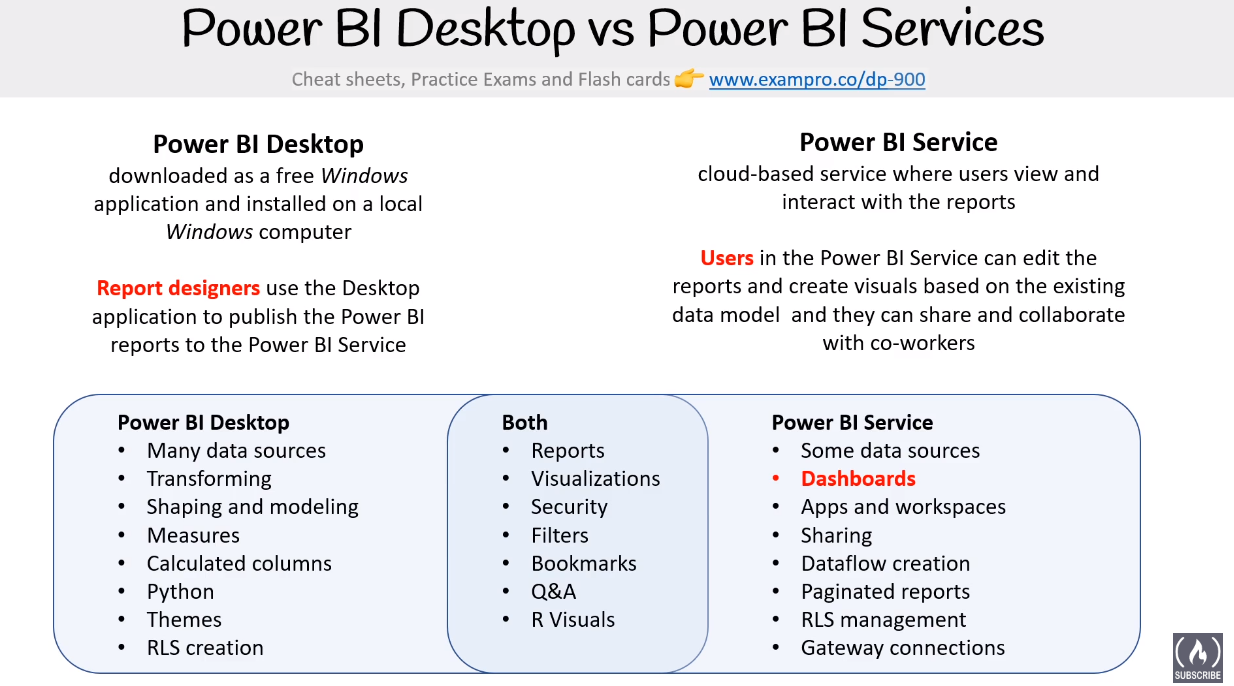
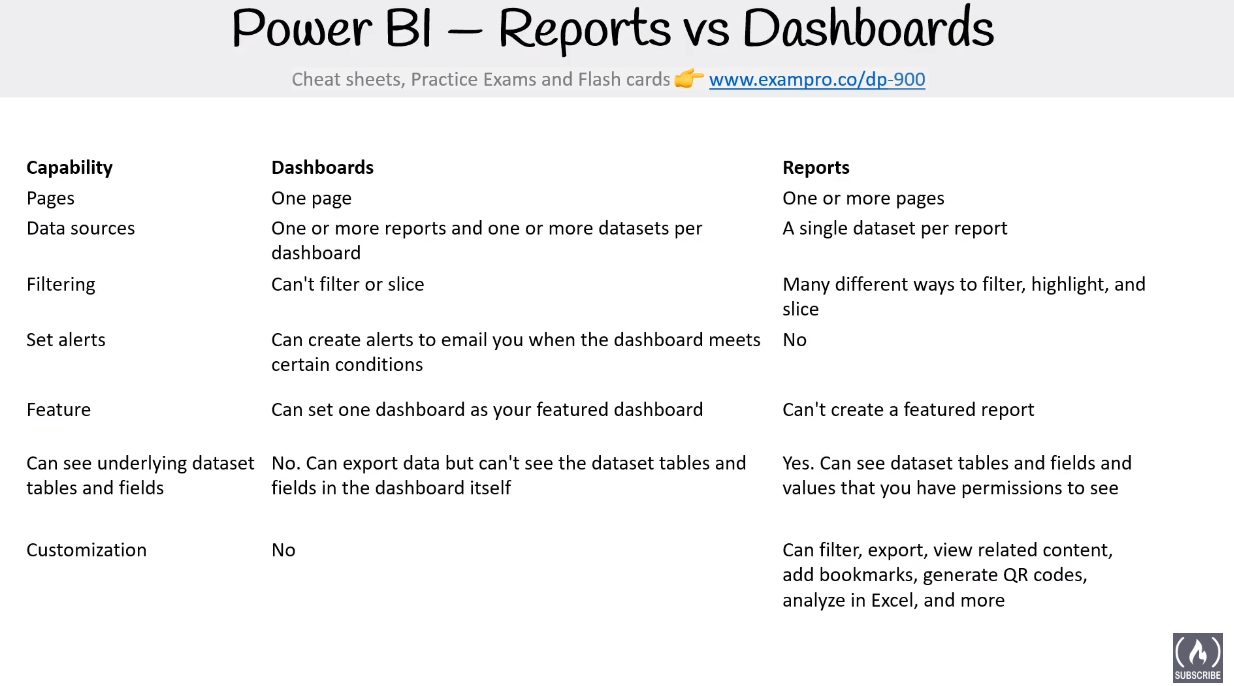

Data Cheetsheets




Relational Databases
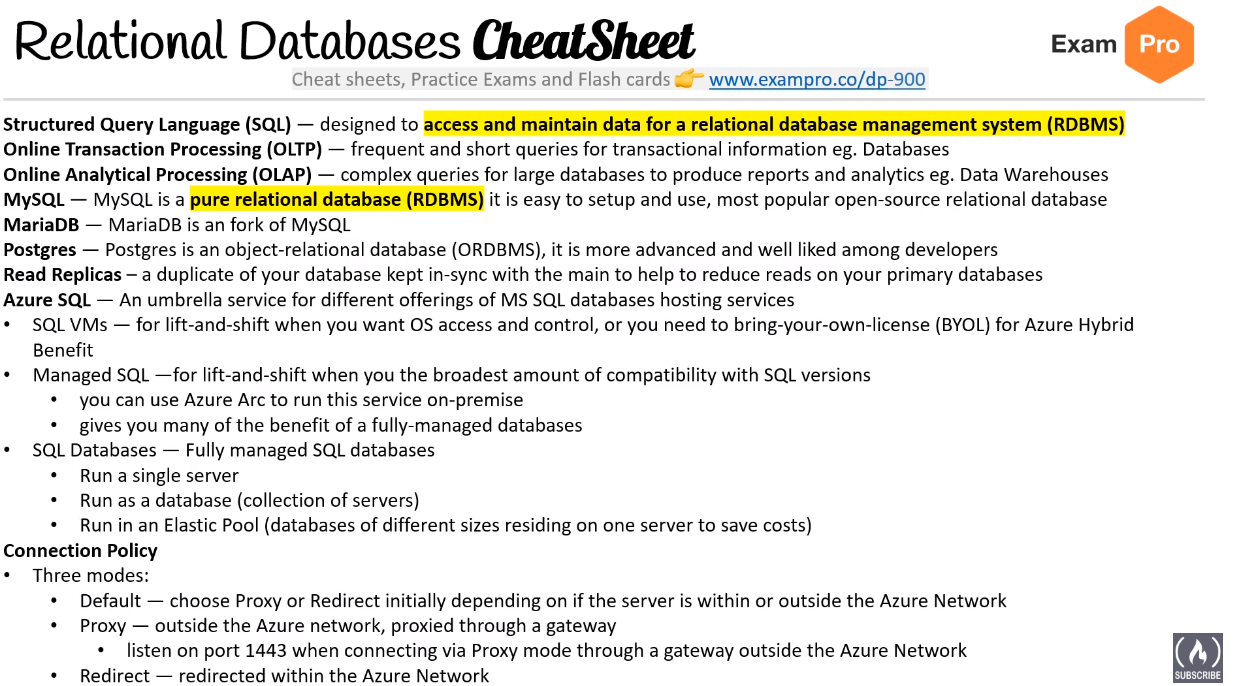
Account Storage

CosmosDB


Azure Synapse and Data Lake

Hadoop

Spark and DataBricks

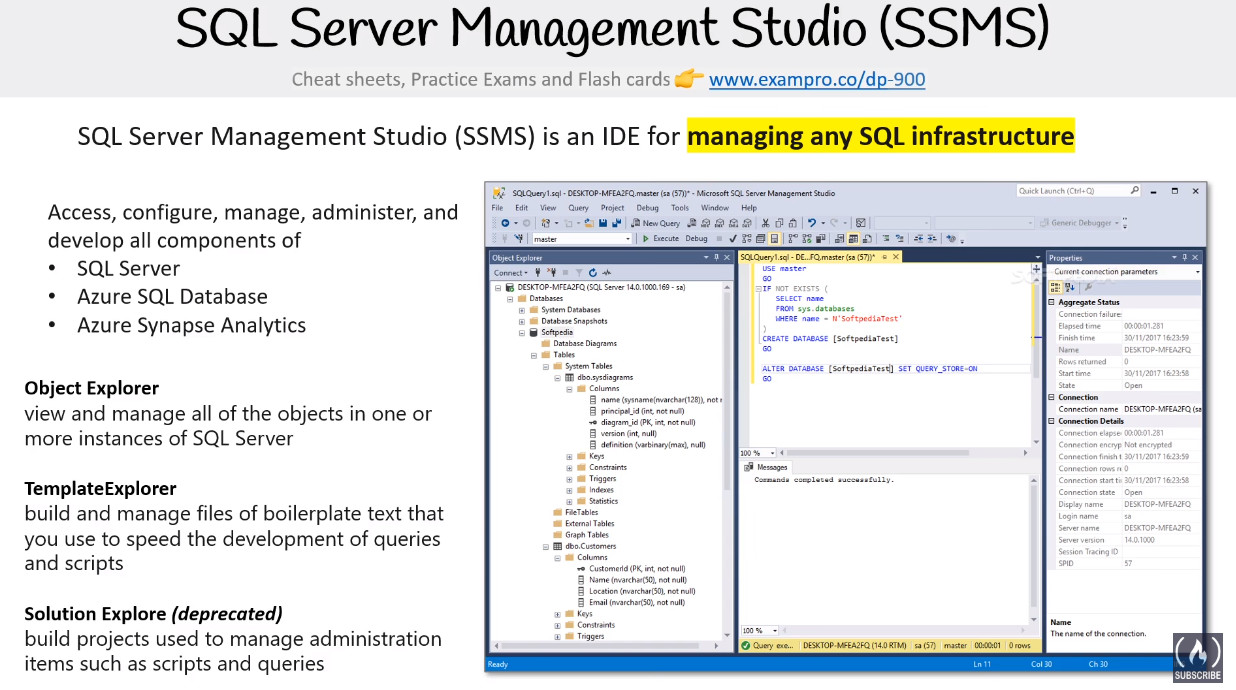
SQL Management Studio (SSMS)




Database Security
